Google vient de lâcher une véritable bombe dans l’écosystème open source. Pendant que tout le monde scrute avec attention la moindre mise à jour payante comme Gemini 3.1 Pro, la firme de Mountain View sort Gemma 4. Et on ne parle pas d’un énième gadget de recherche inutilisable dans la vraie vie. On parle d’une famille de modèles taillée pour tourner sur tes propres machines, sans envoyer tes données dans le cloud.
Le message est clair : l’intelligence artificielle générative de pointe n’est plus réservée aux data centers à plusieurs milliards de dollars. Gemma 4 est pensé pour les développeurs, les bidouilleurs et les entreprises qui veulent du contrôle. La licence Apache 2.0 t’autorise même un usage commercial sans devoir rendre des comptes. Si tu cherches un modèle capable de comprendre du code, d’analyser des vidéos et de tourner sur un simple Raspberry Pi ou une carte graphique grand public, tu es au bon endroit. On va décortiquer tout ça.
À retenir :
- 4 déclinaisons radicales : du E2B pour ton Raspberry Pi au monstrueux 31B Dense pour faire fumer ton GPU local.
- Multimodal natif avec 256 000 tokens de contexte : tu peux lui balancer de la vidéo, de l’audio et des pavés de code sans qu’il bronche.
- Licence Apache 2.0 : c’est ouvert, tu peux l’intégrer dans tes projets commerciaux ou tes agents autonomes sans rendre de comptes à Google.
Les 4 versions de Gemma 4 : quel modèle choisir pour ta bécane ?
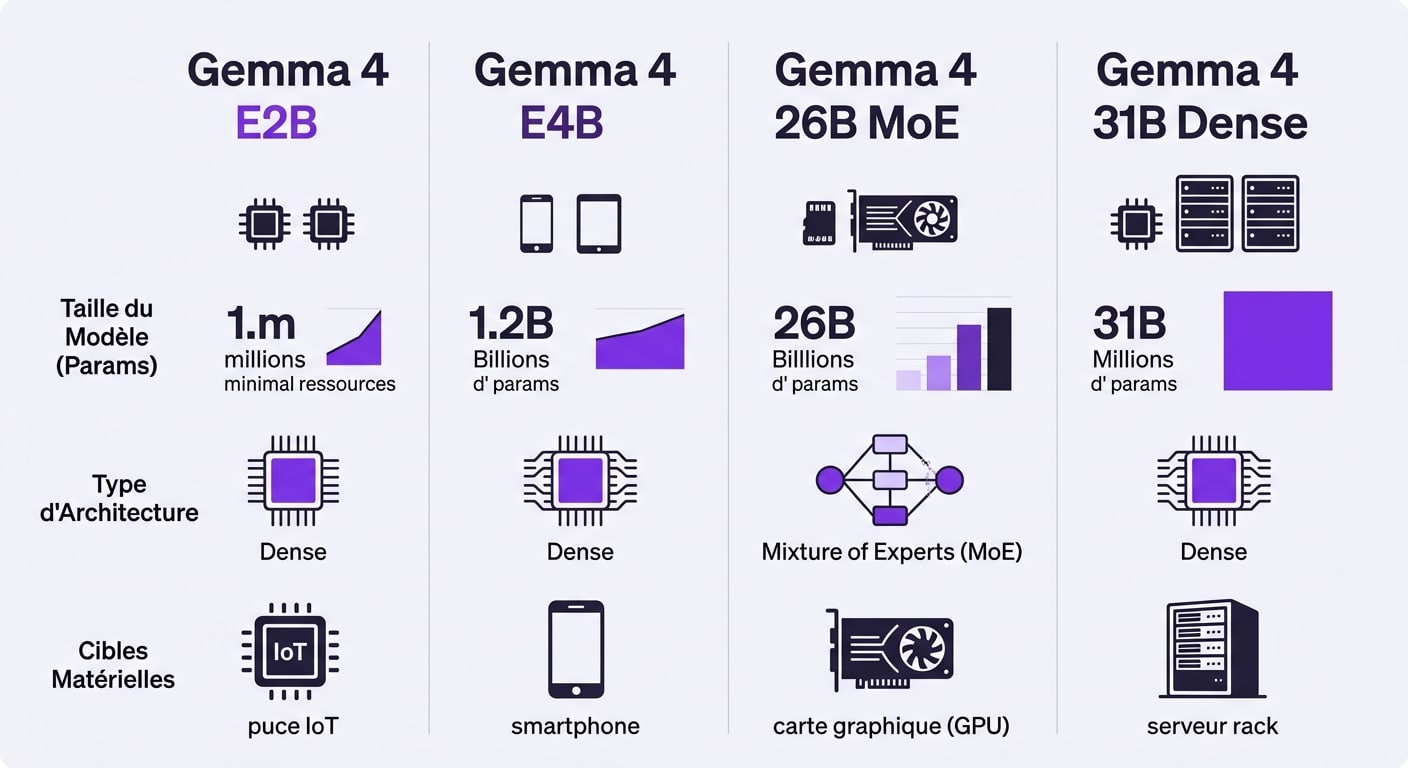
Google n’a pas sorti un seul modèle, mais quatre. Pourquoi ? Parce que tu ne fais pas tourner la même IA sur le navigateur web d’un smartphone et sur un serveur équipé de grosses puces Nvidia. La gamme se divise en deux catégories : les modèles ultra-légers pour l’edge computing (le traitement local sur de petits appareils) et les modèles lourds pour les stations de travail et les serveurs.
Commençons par les petits : les modèles E2B et E4B. « E » pour Edge, « B » pour Billions de paramètres. Ces modèles de 2 et 4 milliards de paramètres sont minuscules à l’échelle de l’IA moderne. Ils sont parfaits pour l’IoT (l’internet des objets), les applications mobiles en natif et même pour tourner directement dans un navigateur web via WebGPU. Ton vieux PC portable de 2018 peut les faire tourner sans transpirer. Ils sont limités sur le raisonnement complexe, mais excellents pour des tâches de résumé rapide, de traduction ou d’assistance vocale basique.
Ensuite, on passe aux choses sérieuses avec les modèles 26B MoE et 31B Dense. C’est ici que tu vas avoir besoin de VRAM (la mémoire de ta carte graphique). Le 31B Dense est un modèle classique : son « cerveau » s’active entièrement à chaque requête. C’est une brute de puissance de calcul, idéale pour le raisonnement mathématique profond ou la génération de code complexe, un peu à la manière de ce qu’on a vu avec Gemini 3 Deep Think. En revanche, il consomme énormément de mémoire.
Le 26B MoE (Mixture of Experts) est beaucoup plus intelligent dans sa conception. Au lieu d’activer ses 26 milliards de paramètres à chaque fois, il n’utilise que les « experts » nécessaires pour répondre à ta question. Résultat ? Il va beaucoup plus vite et consomme beaucoup moins de ressources actives que le 31B, tout en offrant des performances très proches. C’est le roi du rapport qualité-prix en local.
La question de la quantification est cruciale ici. Un modèle 31B en précision standard (16 bits) te demanderait plus de 60 Go de VRAM. C’est impossible pour un PC grand public. Mais en quantifiant le modèle (en compressant son poids) en 4 bits ou 8 bits, tu divises drastiquement ces besoins. En 4 bits, le modèle 31B passe sous la barre des 20 Go de VRAM, ce qui le rend accessible à un Mac M2 avec mémoire unifiée ou une bonne carte graphique de type RTX 4090 ou RTX 3090.
| Modèle | Matériel recommandé | Usage cible idéal |
|---|---|---|
| E2B | Smartphone, Navigateur web, Pi 4 | IoT, domotique vocale, résumé rapide en edge |
| E4B | Raspberry Pi 5, PC bureautique | Assistance mobile, traitement de texte local basique |
| 26B MoE | PC Gamer (RTX 3060/4070), Mac M2/M3 | Agents autonomes, code rapide, bon débit de réponse |
| 31B Dense | Gros GPU dédié (RTX 4090, Mac Studio) | Raisonnement complexe, mathématiques, dev avancé |
Multimodalité et workflows agents : qu’est-ce que tu peux vraiment coder avec ?
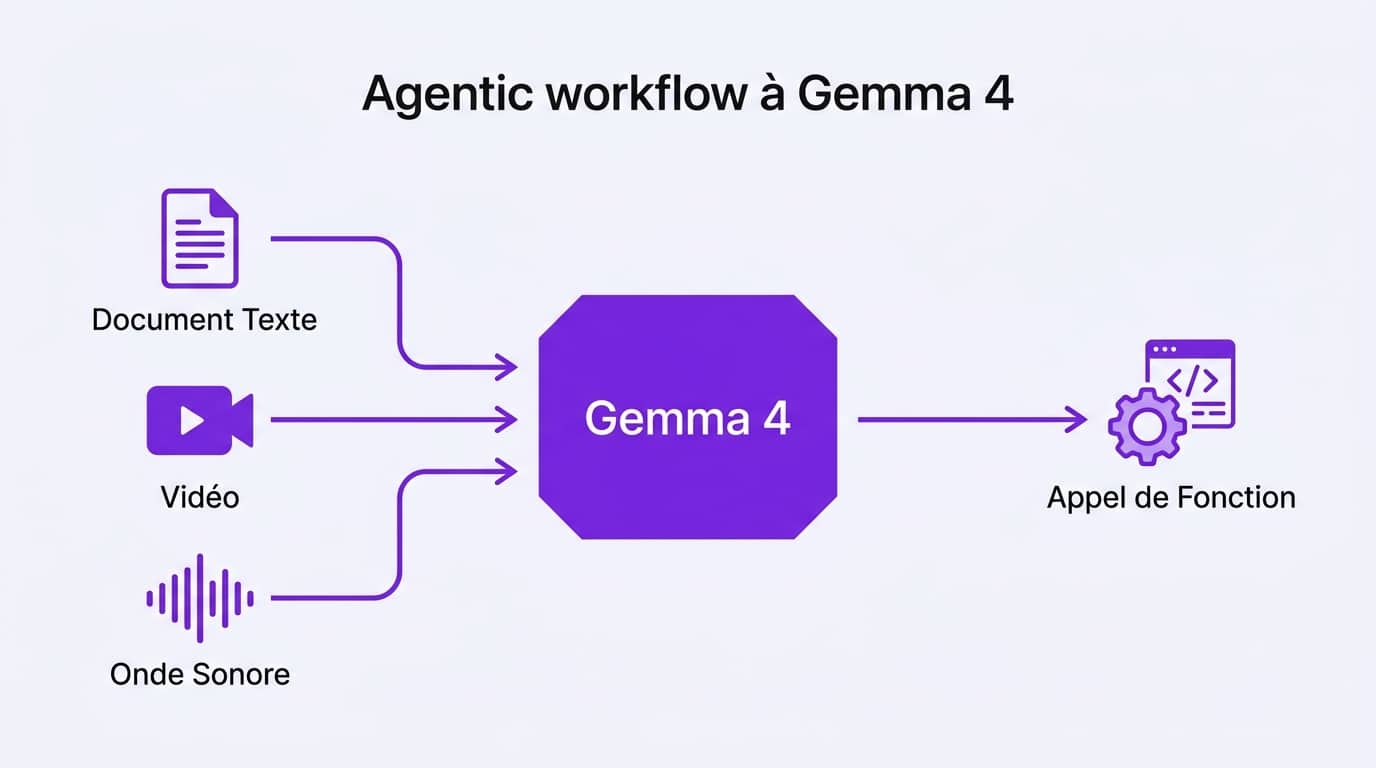
La grosse nouveauté de cette génération, c’est la multimodalité native combinée à une fenêtre de contexte hallucinante de 256 000 tokens. Pour te donner une idée, 256k tokens, c’est l’équivalent d’un livre entier ou d’un énorme répertoire de code source que tu injectes en une seule fois dans la mémoire de l’IA. Tu peux télécharger un projet GitHub complexe, lui balancer tous les fichiers d’un coup, et lui demander de trouver un bug de sécurité croisé entre ton backend et ton frontend.
Contrairement aux anciens modèles qui faisaient du « bricolage » en utilisant des API tierces pour lire des images ou du son, Gemma 4 comprend tout en natif. Tu lui donnes un fichier audio de 30 minutes, il l’analyse directement. Tu lui donnes une vidéo MP4, il analyse les frames sans que tu n’aies à coder un script Python pour extraire les images une par une. Cela simplifie drastiquement le code de tes applications d’IA.
Mais le vrai game changer, ce sont les « Agentic Skills » et le Function Calling natif. Le Function Calling, c’est la capacité de l’IA à comprendre qu’elle ne sait pas faire quelque chose, et à formater une réponse pour déclencher un script que tu as codé. Gemma 4 est surentraîné pour ça. Si tu lui demandes « Quelle est la météo et la charge CPU de mon serveur ? », au lieu de te pondre du texte bidon, il va générer une commande JSON parfaite pour déclencher ton API météo et ton script de monitoring. Cela ouvre la porte à la création de vrais agents autonomes, capables de prendre des décisions et d’exécuter des actions en boucle sur tes machines, une tendance forte que l’on retrouve avec des outils comme Google Antigravity.
Alerte sur la censure : même si Gemma 4 est sous licence libre Apache 2.0 (ce qui est génial), ne confonds pas « open source » et « non censuré ». Google a passé un coup de Kärcher massif sur les données d’entraînement. Le modèle refuse de générer des contenus toxiques, d’aider au hacking malveillant ou de balancer des infos personnelles. Si tu cherches un modèle pour des workflows très spécifiques liés à la cybersécurité offensive (red teaming), il te faudra probablement le fine-tuner toi-même pour contourner ses garde-fous de base.
Sous le capot technique : Dual RoPE, PLE et attention partagée
Comment Google réussit l’exploit de faire des modèles de 26 ou 31 milliards de paramètres capables de tenir tête à des monstres de 70 milliards de paramètres sortis il y a à peine six mois ? C’est grâce à des optimisations mathématiques et architecturales pointues. L’une d’elles s’appelle le Dual RoPE (Rotary Position Embedding). Pour faire simple, quand tu as une fenêtre de contexte de 256 000 mots, l’IA a tendance à oublier où se trouvent les informations au milieu du texte. Le Dual RoPE est une technique qui permet au modèle de conserver des coordonnées précises pour chaque mot, évitant l’effet de « perte de mémoire » classique sur les très longs documents.
Une autre innovation majeure est le PLE (Per-Layer Embeddings). Dans un réseau de neurones classique, la représentation des mots (les embeddings) est globale. Ici, chaque couche d’attention du modèle possède sa propre façon d’interpréter le contexte. Cela donne à Gemma 4 une profondeur de compréhension bien plus fine, particulièrement sur du jargon technique ou des langages de programmation.
Enfin, pour soulager ta mémoire vive, Google utilise massivement le Shared KV Cache (mémoire cache partagée) et l’attention à fenêtre glissante. Plutôt que de stocker l’intégralité du contexte de ta conversation dans la VRAM en permanence, le modèle utilise une attention locale (il se concentre sur les derniers mots) combinée à une attention globale optimisée. Résultat : tu peux maintenir de très longues conversations avec des pièces jointes volumineuses sans que ton application ne crashe avec une erreur « Out Of Memory ». Ces optimisations sont la raison pour laquelle Gemma 4 surpasse son poids sur les benchmarks publics.
Quel modèle Gemma 4 choisir pour ta bécane ?
Trouve la déclinaison parfaite de Google Gemma 4 pour ton projet et ton matériel en deux questions.
Tuto rapide : comment déployer Gemma 4 en local ou sur ton mobile ?
Bon, c’est bien beau la théorie, mais on l’installe comment ? L’avantage de l’écosystème open source actuel, c’est que tu n’as plus besoin d’un doctorat en machine learning pour faire tourner un modèle localement. Sur ton PC, le moyen le plus simple est de passer par le format GGUF et le moteur llama.cpp. Des logiciels ultra-accessibles comme LM Studio ou Ollama ont déjà intégré les modèles Gemma 4. Tu télécharges le logiciel, tu cherches « Gemma 4 » dans la barre de recherche, tu cliques sur le fichier quantifié (compressé) qui correspond à ta RAM, et tu as un ChatGPT local fonctionnel en trois minutes chronos.
Le tip de la rédac : ne te casse pas la tête avec les modèles en précision complète. Choisis systématiquement le modèle 26B MoE quantifié en 4-bits (format GGUF). C’est le meilleur hack actuel. Il offre 95% des capacités de réflexion du modèle d’origine, mais consomme moins de 16 Go de VRAM. Ça tourne de manière totalement fluide sur un Mac M2/M3 de base avec 16 Go de mémoire unifiée ou un PC de bureau équipé d’une RTX 3060 ou 4060 avec 16 Go. C’est l’équilibre parfait entre intelligence et rapidité.
Si tu veux l’intégrer dans un vrai projet Python, la librairie transformers de Hugging Face est prête. En quelques lignes de code avec AutoModelForCausalLM, tu instancies le modèle et tu l’attaques via API en local. C’est la méthode royale pour l’utiliser comme cerveau d’un agent autonome.
Pour le mobile et l’edge computing, Google a poussé ses propres outils à fond. Si tu bidouilles sur un Raspberry Pi 5 ou une carte Arduino avancée pour un projet IoT, utilise LiteRT-LM (anciennement TensorFlow Lite). Cet outil est conçu spécifiquement pour exécuter les modèles E2B et E4B avec une empreinte mémoire dérisoire, en gérant le contexte dynamique. Tu peux l’embarquer dans un robot domestique ou un capteur intelligent déconnecté du web.
Enfin, si tu es développeur mobile, Google propose l’Android AICore Developer Preview. C’est un service système Android qui te permet d’utiliser le modèle E2B directement via une API standard du téléphone, sans avoir à packager le poids du modèle IA dans le fichier APK de ton application. Le modèle est géré par l’OS, utilise les puces NPU du smartphone pour économiser la batterie, et te permet de générer du texte, de résumer des notifications ou d’analyser des images directement sur l’appareil de ton utilisateur. Le futur des apps mobiles est littéralement là.
Toutes les liens utiles sont là, alors amuses toi bien.
Et toi, sur quel matos tu prévois de faire tourner ce nouveau Gemma 4 ? Plutôt bidouille sur Raspberry Pi ou gros GPU dédié ? Balance ta config dans les commentaires !
